문득 요즘 들어서 만들고싶었던 프로그램이 있는데, 석사 진행하면서 만들었던 BP 알고리즘 프로그램의 연장선에 있는 프로그램이다.
그런데 학부 및 석사 때 만들었던 프로그램들은 천재지변으로 모두 유실된 상태라 관련 자료를 찾아보았더니.. 코드는 없고 프로그램만 남은 상태로 발견되었다..
그래서 오늘은 복기도 할겸 하여 해당 프로그램에 대해 작성하려 한다.
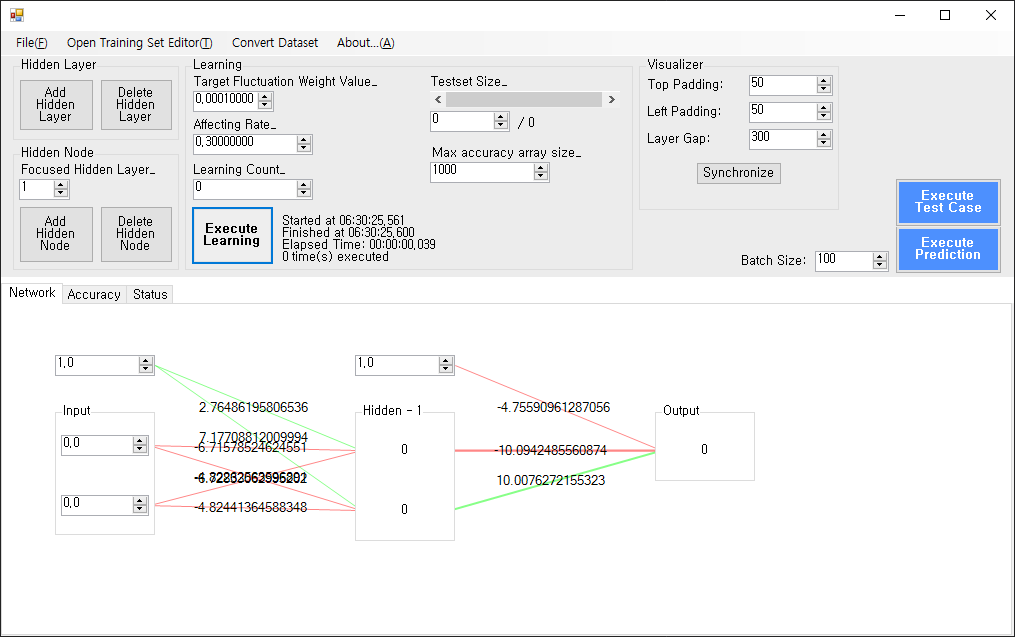
- BP 알고리즘 프로그램 사진
여태 계속 BP, BP 해왔는데, 다시 말하면 BackPropagation(역전파)를 줄여 말한 것이다. 역전파는 ANN(Artificial Neural Network)에서 학습을 시키는 알고리즘인데, 이를 수작업으로(…) 구현한 프로그램이 위의 프로그램이다.
해당 프로그램은 C#으로 구현하였으며, 학습에만 초점을 맞추었기 때문에 속도, 안정성 그 무엇도 고려되지 않았다.
단지 작동이 된다는 것일 뿐…
그래서 이 프로그램으로 무얼 할 수 있는가?
- 다층 퍼셉트론으로 XOR 구현
- 흔히 나이브 베이즈 분류기로 시도해보는 Iris 꽃 분류
이 정도인데, 다행히 저 프로그램으로 학습한 모델은 일반 프로그램에서 사용할 수 있다.
1. XOR 구현
어렴풋이 기억나는 이야기로는, 처음 단층 퍼셉트론이 나왔을 때 컴퓨터에서 계산하는 XOR을 계산할 수 없어서 외면 받은 적이 있다고 한다. 믿거나 말거나 하는 얘기이지만, 이 얘기는 다층 퍼셉트론으로 해당 XOR 연산을 해결함에 따라 딥 러닝이 태동하게 되었다.
아무튼, 위의 프로그램 사진은 XOR을 학습한 사진이며, 학습 데이터와 과정은 아래와 같다.
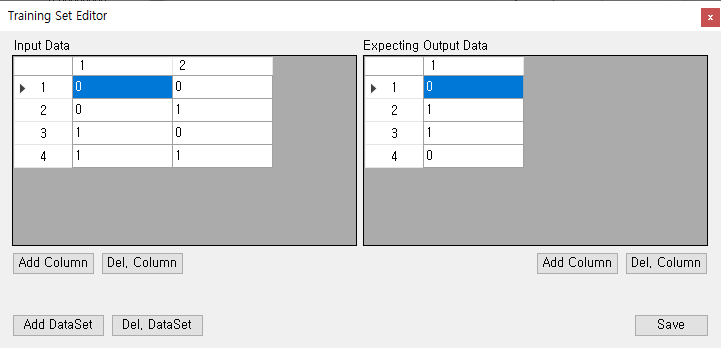
- 학습 데이터
학습 데이터는 노드 1, 2에 대해 특정 값이 들어갔을 때, 기대되는 Output 값을 정의한다. 위의 사진으로 연계하여 설명하자면, Input Data의 Column의 타이틀로 되어있는 숫자 1, 2는 각각의 노드 1, 2를 의미한다. 또한 Expecting Output Data에 적힌 Column의 타이틀인 숫자 1 또한 Output 노드 1을 의미한다. 각 행은 Input 데이터와 Output 데이터를 명시하며, 아래와 같이 정리할 수 있다.
| 학습 데이터 번호 | Input 노드 1의 값 | Input 노드 2의 값 | Output 노드 1의 값 |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 1 |
| 3 | 1 | 0 | 1 |
| 4 | 1 | 1 | 0 |
사실 거창하게 썼지만 결국 XOR의 모든 경우의 수에 대한 내용이다.
암튼 이걸 프로그램에 넣고 돌리게 아래처럼 돌리면
요로케 학습이 된다.
첫 부분을 보면 알겠지만 단층 퍼셉트론으로는 학습이 진행되지 않으며, 히든 레이어를 추가하고 나서야 학습이 유의미 해진다. (Input, Hidden, Output 노드 외에 Input으로 들어가는 값인 1.0으로 된 노드가 하나 더 있는데, 이는 Bias로, 추후 기회가 될 때 추가로 설명하도록 하겠다.)
아래는 실제 실행 결과를 담은 영상이다.

- BP - XOR 실행 결과
2. 실제 학습 데이터 적용
음… 이 내용을 여기에 써도 될지는 모르겠으나.. 랩실 선배님이 쓰신 논문에 위의 프로그램이 사용되었다.
내용을 간추리면 아래와 같다.
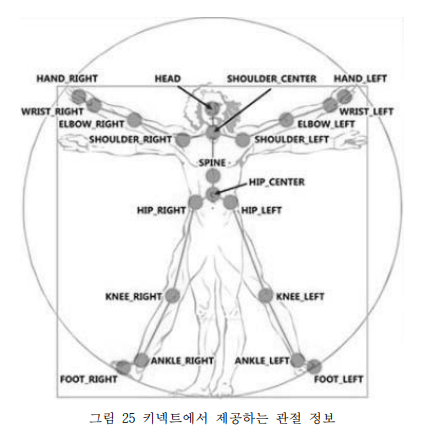
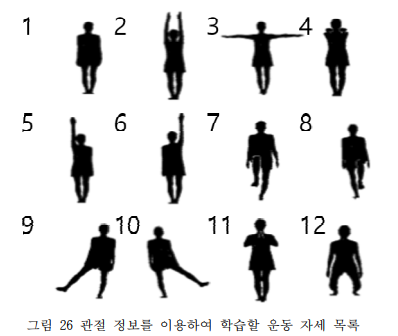
키넥트를 통해 관절 정보를 추출한다. 추출되는 정보는 특정 관절 12개의 x, y 위치이다. 라벨은 그림26으로 명시된 그림과 같이, 1~12의 classifier가 있다.
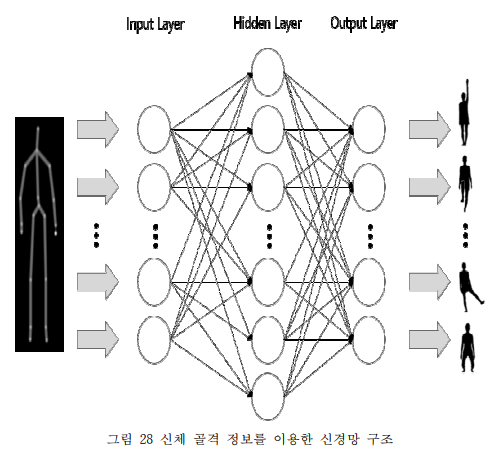
정리하면 위의 그림과 같다.
결과는 생각보다 너무 잘 나와서 놀랬던 기억이 있다.

사진 속 인물은.. 논문 저자가 아닌 다른 인물이다…(지못미..)
암튼, 위의 사진은 12개의 자세를 실시간으로 구분하는 프로그램을 캡처한 사진이다. 동작을 바꾸는 중에는 실시간으로 관절 위치가 바뀌기 때문에 프로그램 오동작이 발생할 수 있지만, 자세가 안정되거나 근접한 자세가 되면 정확히 분류해준다.
정확도는 아래와 같다.
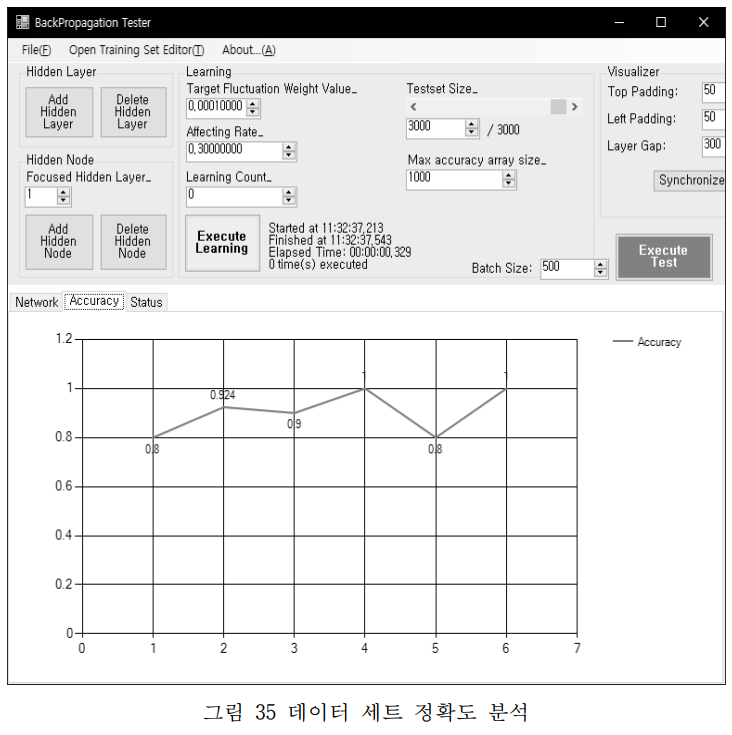
4번째와 6번째 학습에서 Accuracy가 1이 나왔는데.. 오버피팅일 확률이 높다. 굳이 고른다면 2번째 학습 모델을 사용하는게 좋지 않았을까 싶지만 어떻게 진행했었는지는 기억이 나지 않는다.
오늘의 포스팅은 여기까지이다.
그냥 추억 되살릴 겸 해서 적게 되었는데 생각보다 길게 적게 된 것 같다.
다음에는 C++로 해당 프로그램을 작성하는 것으로 진행하고자 한다.
끝!!